Ben jij de baas over jouw data?
Geplaatst op 29 januari 2025 door BIM-Connected
Data gestuurd werken is de toekomst! Om op basis van data tot inzichten te komen, strategieën te bepalen en beslissingen te nemen, is het zaak om over goede data te beschikken. Dat klinkt logisch, maar in de praktijk zijn er nog heel veel organisaties die niet volledig eigenaar zijn van hun data en hier niet volledig de controle over hebben. Waarin zit dit precies en hoe kan het ook anders? In dit artikel nemen we je hierin mee.
De nadelen van applicatie-centrisch werken
Op dit moment werken veel organisaties applicatie-centrisch. Dit houdt in dat zij applicaties kopen om bepaalde processen te ondersteunen, zoals het boeken van uren of het vastleggen van assets in een beheersysteem. Deze applicaties zijn eigenlijk applicatie suites: ze omvatten een applicatie, datastructuur en database. Data is daarmee een onderdeel van de applicaties, maar je kunt hier niet ‘los’ over beschikken. Omdat applicaties verschillende werkprocessen ondersteunen, bekijken ze bijvoorbeeld een asset vanuit verschillende invalshoeken. Over de organisatie heen levert dit datakwaliteitsproblemen op.
Voorbeeld: collega 1 voert in werkproces A in applicatie A een wijziging door op een asset. Collega 2 in werkproces B ziet die wijziging niet omdat hij in applicatie B werkt. In dit geval is de data over de applicaties heen niet meer consistent.
De data van de verschillende applicaties moet daarom op elkaar afgestemd worden: een wijziging in applicatie A moet ook doorgevoerd worden in applicatie B. Helaas is dit makkelijker gezegd dan gedaan.
Deze integratie van systemen kost veel tijd, geld (het neemt doorgaans 35-65% van het IT-budget van een bedrijf in beslag), is ingewikkeld én foutgevoelig – zeker wanneer het aantal applicaties toeneemt. Gaat het eenmaal mis, dan weet je niet meer welke applicatie het nu bij het juiste eind heeft. Hierdoor wordt de informatie in applicaties door de jaren heen steeds minder betrouwbaar en is het applicatielandschap niet meer beheersbaar. Je weet niet langer wat de waarheid is. Het feit dat de data niet ‘los’ uit de applicaties te halen is versterkt dit. Daarnaast ontbreekt het organisaties vaak aan een overzicht van welke data in welke applicatie wordt vastgelegd. Hierdoor weet je als organisatie niet precies welke data je in welke applicatie vastlegt, waarom en of die data up-to-date is. Kortom: er is geen transparantie. De data is niet actueel, betrouwbaar en compleet (ABC). Vanzelfsprekend kun je op basis van deze data dan ook geen goede beslissingen nemen, geen goede strategie bepalen en niet tot goede inzichten komen.
Ook als het gaat om flexibiliteit of wendbaarheid zijn er problemen. Wanneer organisaties – bijvoorbeeld vanwege de aanbestedingswet – over moeten naar een andere applicatie, wordt het nóg ingewikkelder. In dit geval krijg je te maken met:
- Het migreren van data naar de nieuwe applicatie, die een andere datastructuur heeft;
- Het opnieuw opzetten van alle integraties die de oude applicatie had;
- Tijdelijke negatieve gevolgen voor lopende werkprocessen: deze kunnen weken tot wel maanden hinder ondervinden door het tijdelijk bevriezen van applicaties om de data over te zetten.
Kortom: dit soort trajecten zeer ingewikkeld, langdurig en kostbaar. Om de data te herstellen, geven organisaties miljoenen uit aan dataverbetering. Maar dit is slechts een tijdelijke oplossing. Na 10 jaar bevinden zij zich weer in dezelfde situatie.
Wat werkt dan wel?
Om data gestuurd te werken, moet je over die data beschikken die voor jouw organisatie van belang is én is het noodzakelijk dat deze data betrouwbaar is. Dit doe je door data op de eerste plek te zetten, oftewel: door data-centrisch te werken. De geschetste problemen ontstaan namelijk omdat data niet beschikbaar, moeilijk verkrijgbaar of lastig overzetbaar is. Zorg ervoor dat je als organisatie zelf de volledige controle hebt over alle data die je als organisatie nodig hebt. Hierbij helpt het als je deze data met open standaarden vastlegt zodat je geen afhankelijkheden hebt naar leveranciers voor je eigen data. Open standaarden zijn onafhankelijk van applicaties, dus je loopt geen risico dat personen kennis opdoen die verloren gaat als een applicatie wordt vervangen. Een heel belangrijk voordeel!
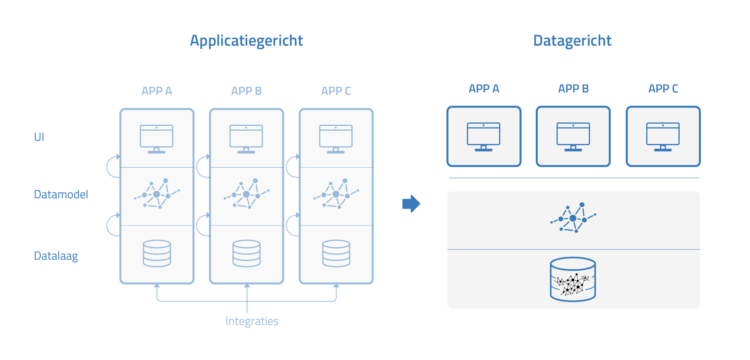
Zoals eerder al beschreven zijn applicaties doorgaans applicatie suites, bestaande uit data, een datastructuur en een app: de user interface of functie. Wanneer je data centraal gaat stellen, is het zaak om expliciet onderscheid te maken tussen data, datastructuur, koppelingen en applicatie. Zo kun je deze apart beheren en ook apart onderhouden, ontwikkelen en waar nodig applicaties vervangen, verwijderen of toevoegen terwijl je jouw data en datamodel behoudt. Hierbij heb je bovendien altijd toegang tot jouw data. Ook datamigraties zijn verleden tijd.
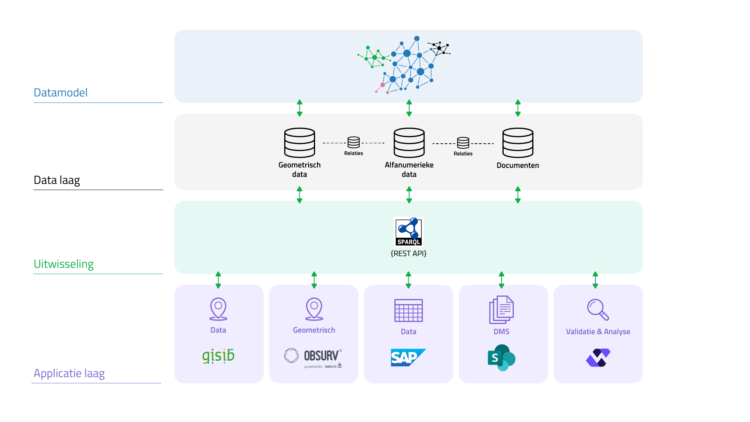
De vier lagen van data-centrisch werken
- Datastructuur: De datastructuur (ook wel het datamodel) is het hart van de data die je wilt verzamelen. Hierin leg je als organisatie vast wat de databehoefte van de organisatie is en hoe de data met elkaar verbonden is. Hiermee maak je het transparant welke informatie je waarom en voor wie wilt vastleggen.
- Data: De data in de data-laag is gebaseerd op de datastructuur die je hiervoor opstelt en moet hieraan voldoen. Door je eigen data losstaand op te slaan, heb je hier altijd toegang tot én kan deze voor meerdere doeleinden worden gebruikt.
- Applicaties: Applicaties zijn er voor de functionaliteit. De applicatie leest data uit, doet haar “magic” en slaat de resultaten weer op. De aanpassingen van de data worden weer teruggeschreven naar de datalaag. Wanneer je kiest voor data-centrisch werken, zijn applicaties niet leidend, maar volgen deze jouw databehoefte.
- Koppelingen: Via koppelingen kan data opgehaald worden en verstuurd worden. Ook kunnen hierin de toegangsrechten beheerd worden, zoals welke applicatie welke rechten heeft tot welk deel van de data (zoals Create, Read, Update, Delete). De koppelingen bevinden zich tussen de applicaties en de datalaag of tussen de datalaag en andere datalagen.
We zetten nog even kort de voordelen van data-centrisch werken op een rij:
- Je hebt als organisatie inzicht in welke informatie je wilt vastleggen, voor wie je deze wilt vastleggen en waar deze wordt vastgelegd, dit biedt transparantie en reduceert kosten voor dubbel vastleggen en kosten die voortkomen uit onduidelijkheid.
- Je bent de baas over jouw data, waardoor je hier altijd toegang tot hebt, deze kunt hergebruiken en er alles uit kan halen wat je wilt.
- Als je eigenaar bent van de data kun je als organisatie ook zelf instellen welke applicaties toegang krijgen tot welke data. Je bent hierbij direct in control.
- Je data is betrouwbaar: er is één single source of truth waar jij van op aan kunt in plaats van datasilo’s in verschillende applicaties
- Door één centrale datalaag verlaag je het aantal koppelingen enorm. Daarmee vergemakkelijk je het beheer en verlaag je ook de kosten drastisch.
- Door deze scheiding van data, datastructuur en applicatie minimaliseer je vendor lock-ins en ben je minder afhankelijk van leveranciers.
- Omdat je zelf over alle data beschikt zijn datamigraties niet meer nodig.
- Data komt op plaats 1 te staan, applicaties komen op plaats 2.
Moet nu direct alles op de schop?
Nee. Organisaties kunnen in principe blijven werken met de applicaties die ze hebben. Maar: ze moeten wél de eigen datastructuur expliciet gaan vastleggen en zorgen voor een centrale data-laag, die hun single source of truth is. Het uiteindelijke doel is dat bestaande applicaties hiermee gaan communiceren, in plaats van met elkaar. Hierdoor komt er meer overzicht en werkt iedere applicatie met dezelfde, correcte data.